前言
上周是收获最多的一周,先是被大佬套路如何排查问题,之后又一脚踩进Go的坑中,最后又见识了用户各种薅羊毛的路数。在系统设计中,通常要要秉承两条原则:
- 上层保护下层,作为主调方要从参数,流量等保护下层接口,面对架构复杂即使不能保护下层接口,也要有保护的意识
- 下层不信任上层,作为被调方要对接收的参数验证,来源验证,防止被恶意攻击。在内部系统中参数还好控制,一旦暴露在外部,什么牛鬼蛇神都能传进来。要强调一句对于基本数据类型的范围一定要有一个认识,不只是2的n次方-1什么的,而是要具体到大约多少亿范围。在工作中发生过调用方传超出范围的字符串,而调用integer.parseint抛出runtime exception但没有方法catch导致调用超时无数据返回的情况。无数据返回在RPC调用中非常致命,只能等超时返回,严重降低并发。也就是说只要调用必须控制超时时间,执行异常必须返回信息,不能等待超时断开连接返回空。
高并发系统中有三种常见方式来保护系统:缓存、降级和限流。缓存和降级在缓存使用系列讲过了,这回来讲限流算法。
常见的限流地方有:限制并发总数(数据库连接池、线程池、单ip并发数)、限制瞬时并发数、限制时间窗口内的平均速率等等。
1. 限流算法
1.1 漏桶算法(leaky bucket)
漏桶作为计量工具时,可以用于流量整形和流量控制,漏桶算法的描述如下:
- 容量固定,按照固定速率流出水滴
- 如果桶为空,则不流出水滴
- 可以按照任意速率流入水滴到漏桶
- 如果流入水滴超出了桶的容量,流入的水滴被丢弃,桶的容量不变
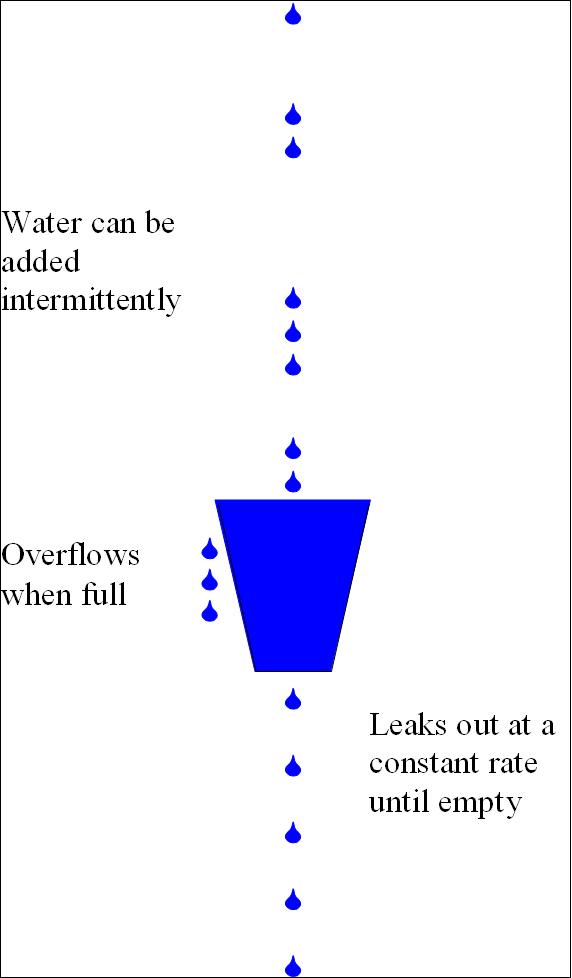 图来自维基百科
图来自维基百科
1.2 令牌桶算法(token bucket)
令牌桶算法是存放固定容量令牌的桶,按照固定速率往桶里添加令牌。令牌桶算法的描述如下:
- 每 1/r 秒往桶中添加一个令牌
- 桶中最多存放b个令牌,当桶满时新添加的令牌被丢弃
- 当n个字节的数据包到达时
- 如果桶中存在多于n个令牌,删除n个令牌,将数据包发送到网络上
- 不足n个令牌,不会删除令牌,数据包被丢弃或者放入缓冲区
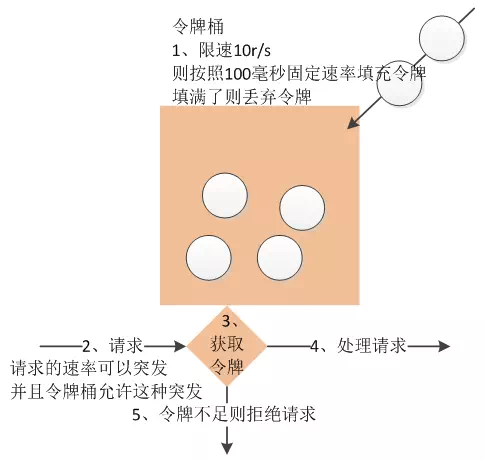 图来自参考1
图来自参考1
漏桶算法和令牌桶算法的区别:
- 令牌桶算法允许一定程度的并发,只要桶中有令牌就可以。漏桶法通过限制常量流出速率从而平滑流入速率
- 两个算法的实现可以一样,但是方向是相反的,对于相同参数得到的限流效果是一样的
1.2 计数器法和滑动窗口法
计数器法相对其它算法是最容易实现的,当然各种场景下的计数器法都有致命问题,GC中的计数难以处理循环引用,这里的计数器面对临界值也有问题。比如我们统计1分钟内的访问次数,限制最多为100,每次有请求计数器加一,如果59秒时来了100个请求,1分钟时又来了100个请求,相当于2秒内来了200个请求,超出限制。有什么解决办法呢?想一想有什么协议也需要控制流量,TCP!TCP中的滑动窗口就是很好的实现方式。这里不再写了。可以参考链接里的第二篇